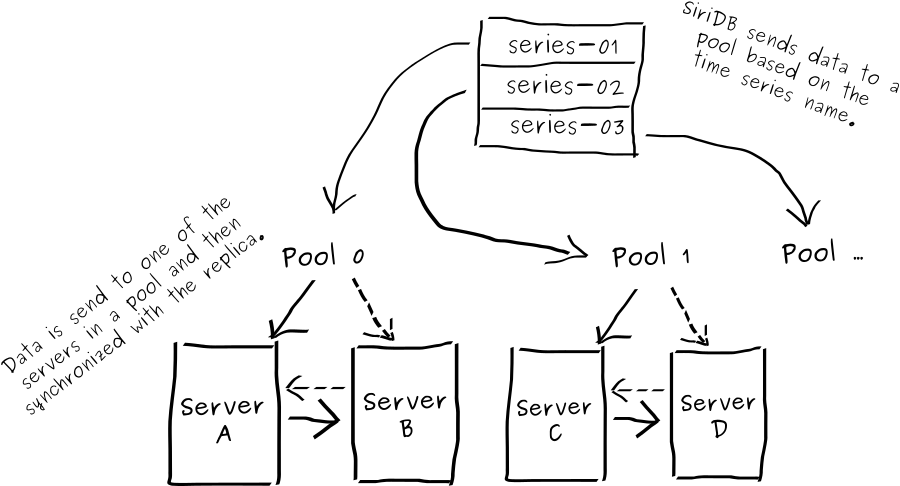
Server, Pool & Replica
SiriDB can distribute time series across multiple pools and for redundancy each pool can have two servers. If one server in a pool fails; the other server, which is a replica, will still be able to handle all requests so the database can still be used. This is also helpful in case you want to install a new version of SiriDB. By upgrading one server in each pool at a time, upgrading can be done without any downtime.
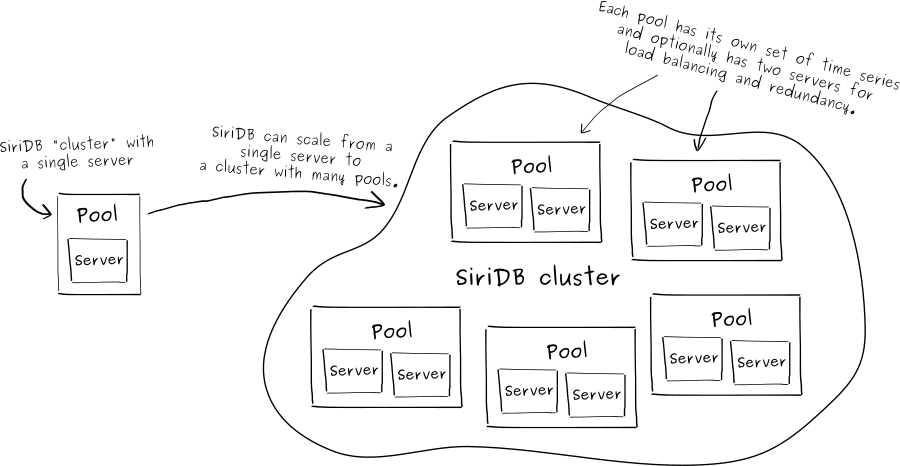
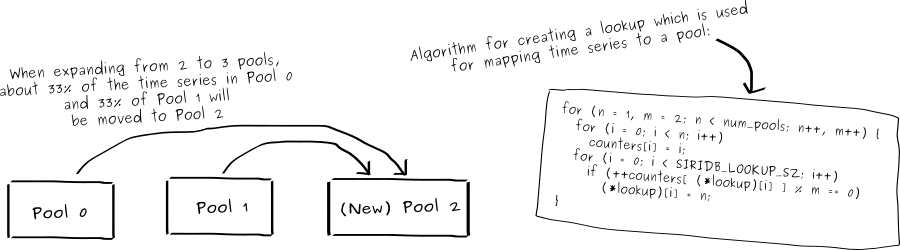
Instead of a global index for the time series, SiriDB uses a custom crafted algorithm to map time series to a pool. This algorithm is designed in such a way that, when adding a new pool, data is only moved from existing pools to the new pool and not between existing pools. During the process of extending a database with a new pool, a copy of the old lookup is kept to make sure queries and inserts keep working. SiriDB intentionally runs the expansion with low priority in the background so the database remains fully operational when a new pool is being added. The same is true for adding a second server to a pool. SiriDB will replicate all data to the new server in the background and the new server becomes a full cluster member as soon as the initial replication is finished.
When new data is received by SiriDB, it first determines in which pool the data should be stored, after which the data is sent to the specific pool. In case a pool has two servers, one is randomly chosen and this server will be responsible for updating the replica by using a fifo buffer on disk.